
随着大语言模型(LLM)的发展,越来越多的开发者希望在本地运行这些模型,以便更好地掌控数据安全、避免延迟、并利用自有硬件的计算能力。但是大多数 AI 模型训练和推理的框架通常对 NVIDIA 的 CUDA 提供支持,而 AMD 显卡的兼容性相对较弱。本文将介绍如何利用 ROCm 和 ollama 在本地运行大语言模型。
准备工作
确认自己的 AMD 显卡是否支持 ROCm
ROCm supported GPUs
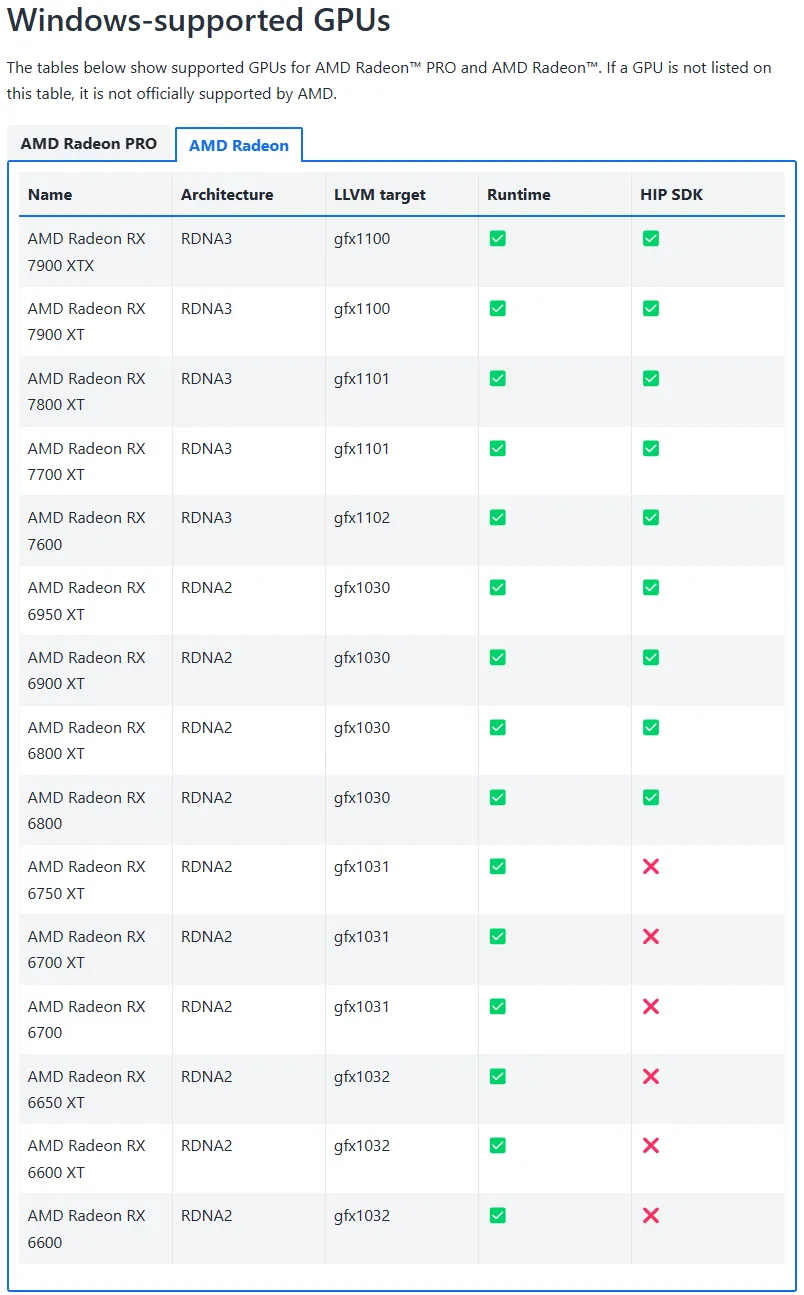
对于官方支持 HIP SDK 的显卡,只需要下载并安装 AMD 官方版本的 ROCm 和 Ollama 的官方版本就能直接使用。
本文主要是介绍对于官方不支持的显卡应该如何安装并使用 ROCm 和 ollama。
下载 ROCmLibs
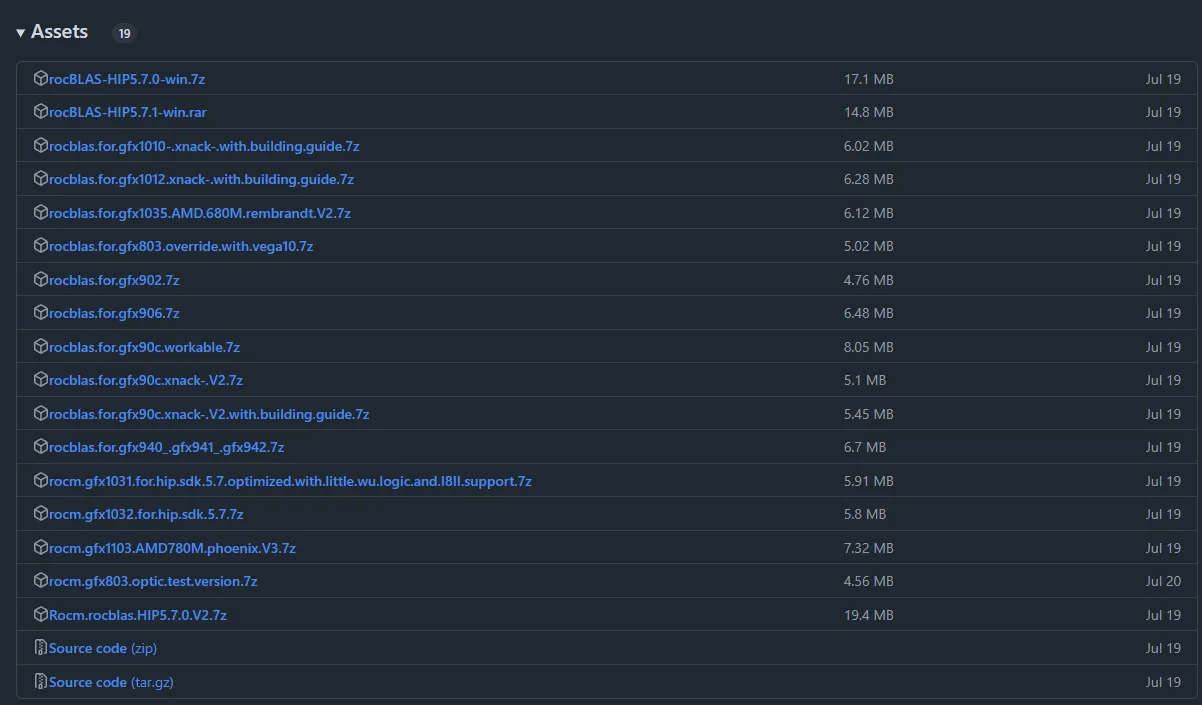
比如我的显卡是 AMD Radeon RX 6750 XT 型号是 gfx1031,那么我就可以选择下载
- gfx1031:
rocm gfx1031 for hip sdk 5.7 optimized with little wu logic and I8II support.7z
下载安装 ollama-for-amd
对于官方不支持的显卡才需要用这个版本,也能自己编译,官方支持的显卡只需要下载安装官方版本的就行了。
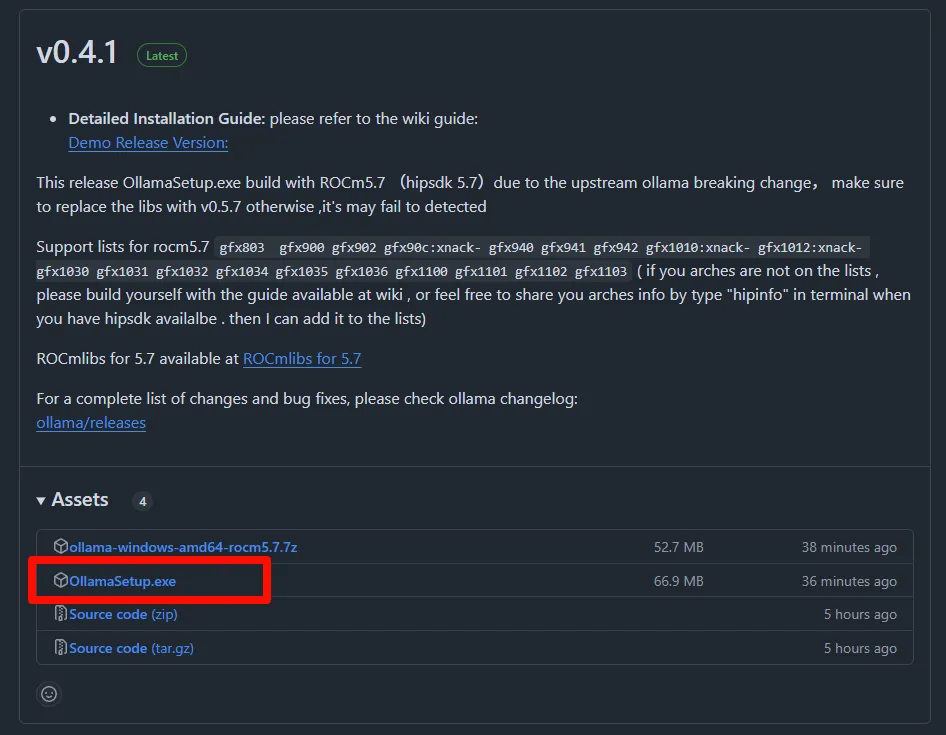
下载完成后运行安装包一键安装完成,安装成功后运行 ollama
修改 ollama-for-amd
从 log 中可以看到 ollama 没有跑在显卡上,输出没有发现兼容的显卡
1 | source=amd_windows.go:138 msg="amdgpu is not supported (supported types:[gfx1103])" gpu_type=gfx1031 |
现在就需要用到之前下载的 ROCmLibs
我的显卡型号是 gfx1031 所以对应 rocm gfx1031 for hip sdk 5.7 optimized with little wu logic and I8II support.7z
打开软件安装目录,比如这是我的安装路径 C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama
- 将压缩包中的
rocblas.dll替换C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama\rocblas.dll - 将压缩包中的
library文件夹替换C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama\rocblas\library
退出 ollama 并重新运行
1 | source=types.go:123 msg="inference compute" id=0 library=rocm variant="" compute=gfx1031 driver=6.2 name="AMD Radeon RX 6750 XT" total="12.0 GiB" available="11.8 GiB" |
就能在 log 中看到成功识别到显卡了
现在运行模型就能运行在显卡上了,速度也是快了
安装并运行模型
在ollama模型库上查看支持哪些模型
比如要安装运行qwen2

参考资料
- https://github.com/likelovewant/ollama-for-amd/wiki
- https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU
- https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html
- https://ollama.com/blog/amd-preview
有什么问题可以发表评论一起讨论交流学习 
如果觉得这篇文章对你有帮助,可以回复表情、发表评论、分享给更多的朋友  谢谢
谢谢 
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




